
By Christophe Monget, CEO at MoiraCorp. A working case study in turning regulatory complexity into a manageable technical problem.
Applying for an FCA API (Authorised Payment Institution) licence is where human potential goes to die in a mountain of paperwork. The Payment Services Regulations 2017, the FCA’s policy notes, the granular requirements on ownership structures and safeguarding arrangements — together, thousands of pages, with a margin for error that approaches zero. The conventional route through all of this is a large team, a long timeline, and a quiet hope that nothing critical has been overlooked.
When I came to MoiraCorp’s own FCA application, I decided to do it differently. Not because I had a clever new methodology, but because regulatory complexity is a textbook AI problem and I was curious what an honest stress test would show.
The hard truth about regulatory work
Regulatory complexity is not the enemy. The enemy is the way the work is normally done — reviewing and cross-referencing thousands of pages by hand, requiring a team of people with different specialisms working in different documents at different times. It is slow, it is expensive, and it introduces exactly the kind of inconsistency a regulator notices.
What was striking, when I sat down to plan our application, is that the underlying problem is not really legal at all. It is an information retrieval problem with a compliance wrapper. Once I framed it that way, the solution became obvious.
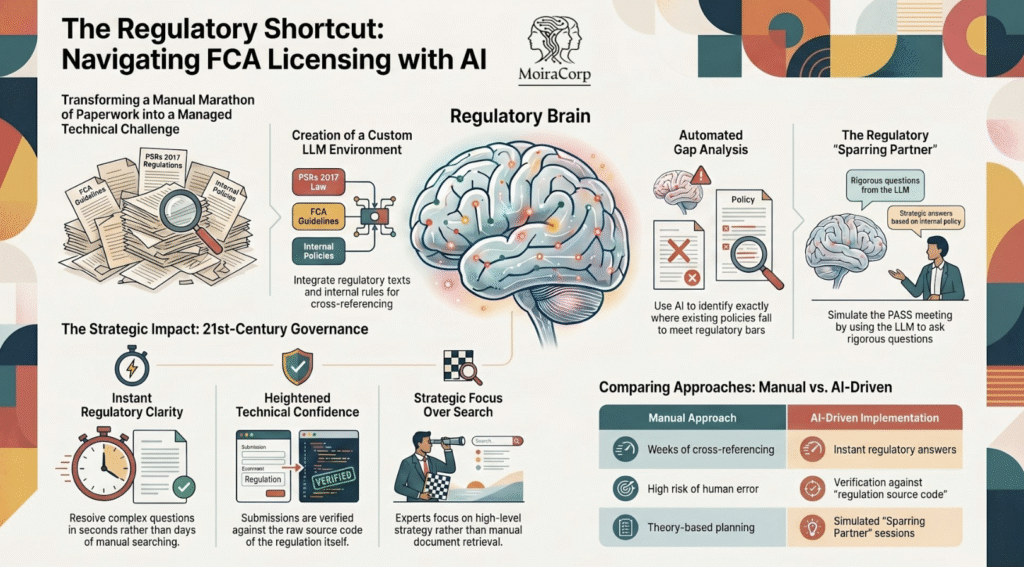
What we built
I set up a custom LLM environment with three corpora loaded in:
- The full text of the Payment Services Regulations 2017
- The FCA’s published guidelines, policy notes, and Approach Documents relevant to API authorisation
- Our own internal company policies, drafts, and supporting documentation
The technical implementation was not exotic — a retrieval-augmented generation setup with structured chunking, semantic search across the corpus, and a prompt structure tuned for regulatory questions. The interesting part was not the architecture. The interesting part was what became possible once the model could actually see all three corpora at once.
What it changed
Three things, specifically.
1. Instant clarity on complex requirements.
Questions that would have required half a day with a senior consultant — “Where does the FCA distinguish between safeguarding by segregation and safeguarding by insurance, and what evidence does each require?” — were answered in seconds, with citations back to the source paragraphs. I could ask, follow up, refine, and move on. The hours saved here alone justified the entire setup.
2. Policy verification as a stress test.
This was where the model earned its place. I asked it to read each section of our drafted policies against the regulatory requirements and flag any gaps — places where our policy met the bar, places where it was thin, and places where it didn’t address the requirement at all. The output was not perfect. But it surfaced material gaps in our governance documentation that we had not spotted ourselves, and it did so in a single afternoon.
The model was not replacing legal judgement. It was making the legal judgement faster, more thorough, and more defensible.
3. PASS meeting preparation.
The FCA’s pre-application support meeting is the regulatory equivalent of an oral exam. I used the LLM as a sparring partner — feeding it the harder questions the regulator might ask, and using its responses (and its limitations) to shape how the management team prepared. Some of the questions it generated were ones I would not have anticipated. That was the point.
What I would tell anyone considering this
Three honest reflections.
First, the LLM is not the consultant. It cannot make a regulatory judgement and it cannot stand in front of the FCA. What it does is reduce the friction of working with the source material — and that friction is where most of the time and cost in a compliance project actually lives.
Second, the quality of the corpora matters more than the model. A general-purpose LLM with web access is dangerous for this work. A targeted environment with the regulation itself, the official guidance, and your own documentation is a fundamentally different tool. Most of the value came from the discipline of curating what the model could see.
Third, the savings compound. The same setup that supports a single application becomes an ongoing compliance asset. When regulations update — and they will — the same environment surfaces what has changed and how it affects existing policies. The first application pays for the setup. Everything after that is upside.
The broader point
We did not save time by skipping steps. We saved time by reading the regulation more directly, more completely, and more honestly than the conventional process allows. Innovation in compliance is not about new tools. It is about closing the gap between what the regulation actually says and how a firm responds to it.
The PSRs 2017 are not going to get shorter. The next set of regulations will not be simpler. The firms that work this out will spend less time on compliance and more time on the business they were authorised to run.
