
By Dimitri Limata, COO at MoiraCorp. With the IHT regime changing in April 2027, IFAs face a capacity squeeze that AI is expected to absorb — and a compliance question they cannot avoid.
By April 2027, every IFA in the UK will need to revisit every client’s IHT plan. 213,000 estates with pension wealth come into scope. Around 10,500 will face an actual IHT charge. Most firms have one or two client touchpoints a year to get through it all.
Capacity is going to bite hard. So naturally, every adviser firm I speak to is looking at AI.
The market is moving fast
The capacity gains being reported are not marginal. Suitability reports are dropping from four to six hours to under twenty minutes, with some benchmarks showing eighty-percent-plus time reductions. The technology works. The case for adopting it is obvious. So far, so straightforward.
Then it gets complicated.
The FCA is not going to introduce AI-specific rules
Nikhil Rathi has confirmed this on the record. There will not be a separate AI rulebook for financial services. Firms will be expected to operate within the frameworks that already exist: Consumer Duty, SM&CR, operational resilience, and UK GDPR — in particular Article 32 on the security of processing.
At the same time, the ICO has been clear that data minimisation, including redaction of personal data before it reaches an AI system, is part of responsible AI use. Article 32 is not optional.
For an adviser firm, this creates a problem the regulators have not solved for you: how do you actually let your team use AI without breaking any of those rules?
The three options most firms consider, and why none of them work
Ban AI outright. Staff route around the ban. They use ChatGPT or Copilot on their personal devices, or quietly inside browser tabs. The firm has no visibility, no audit trail, and no idea what client data has left the building.
Sanction enterprise tools only. A reasonable instinct, but the same problem in a different shape. Most actual AI usage still happens outside the sanctioned environments — in personal accounts, on phones, in tools the firm has not approved. Sanctioning Microsoft Copilot does not stop someone pasting a client’s pension details into a free chatbot at home.
Do nothing. Wait and see. The risk here is the one regulators care about most: when scrutiny increases, the firm has to evidence that its processing of personal data was compliant with Article 32 throughout. “We did not know” is not an answer.
None of these options give you what you actually need, which is the ability to use AI safely, with evidence, at scale.
What a compliant AI workflow actually looks like
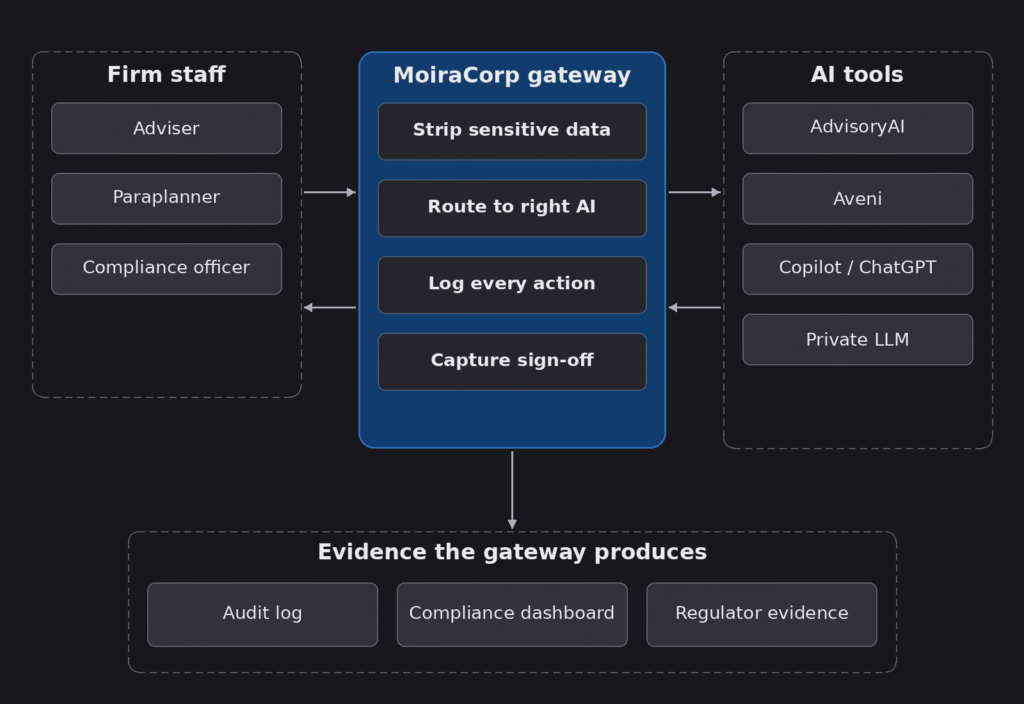
The answer is more architectural than technical. What we are seeing work, across the adviser firms we talk to, is a single controlled layer that sits between firm staff and any AI tool they want to use. That layer handles four things, always, regardless of which AI is on the other side:
- Strip sensitive client data before any request leaves the firm’s environment
- Route the request to the appropriate AI tool for the job — AdvisoryAI, Aveni, Copilot, ChatGPT, a private LLM, whatever fits
- Log every interaction — who asked what, when, against which client matter, and what came back
- Capture human review and sign-off aligned to SM&CR responsibilities — nothing reaches a client without an accountable person approving it
Whether the interaction is a chat interface used by a paraplanner or an API call from another platform, the same four controls apply. The architecture does not care which AI is being used. It cares that it is being used safely.
What the gateway actually produces
The faster workflows are the obvious benefit. They are not the most important one. The most important output of an architecture like this is the evidence:
- A complete audit log showing every AI interaction tied to a client, an adviser, and a piece of work
- A compliance dashboard giving the COO and compliance officer real-time visibility on usage patterns and exceptions
- Regulator-ready evidence when the FCA, the ICO, or a section 166 reviewer asks how AI is being used and whether the firm’s controls are working
The compliance position becomes provable, not asserted. That is the difference that matters.
Why this matters now and not in 2027
April 2027 is the deadline that triggers the IHT capacity problem, but it is not the deadline for the compliance problem. Article 32 and Consumer Duty already apply. If your team is using AI today — and they are, whether you have approved it or not — the obligation to evidence safe processing is live right now.
The firms that work this out early will have two advantages by the time IHT 2027 arrives. They will have the capacity to handle the workload, and they will have the architecture to handle it compliantly. The firms that wait will be solving both problems under pressure, with the regulator watching.
The capacity problem and the compliance problem are the same problem. Solve them once, with one architecture.
